
攻防世界,数据接口采集
文亮
客户信息
数据采集非常好,还会找你
案例介绍
案例背景
随着互联网的发展,网站的数量日益增多,每天都会产生大量的新闻内容。然而,这些内容分散在各个不同的网站,对于用户来说,如果想要获取多个网站的新闻,就需要分别访问这些网站,这无疑增加了用户的负担。
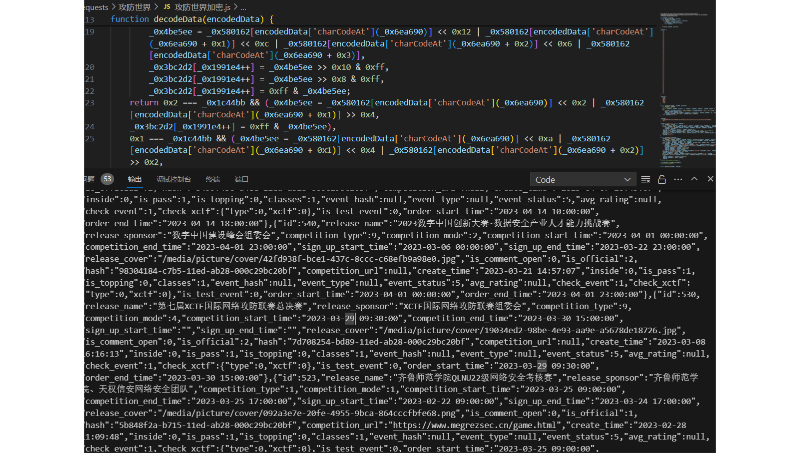
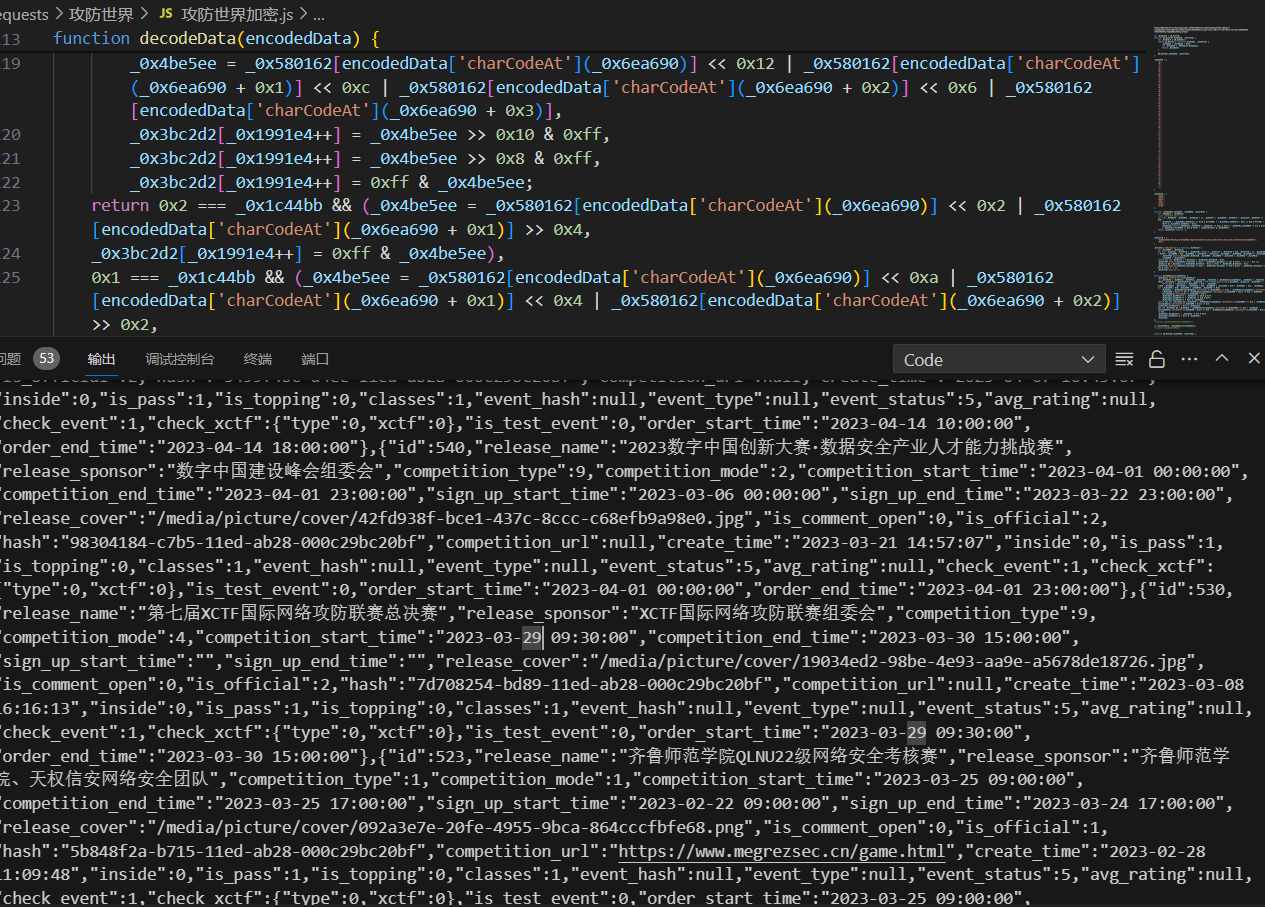
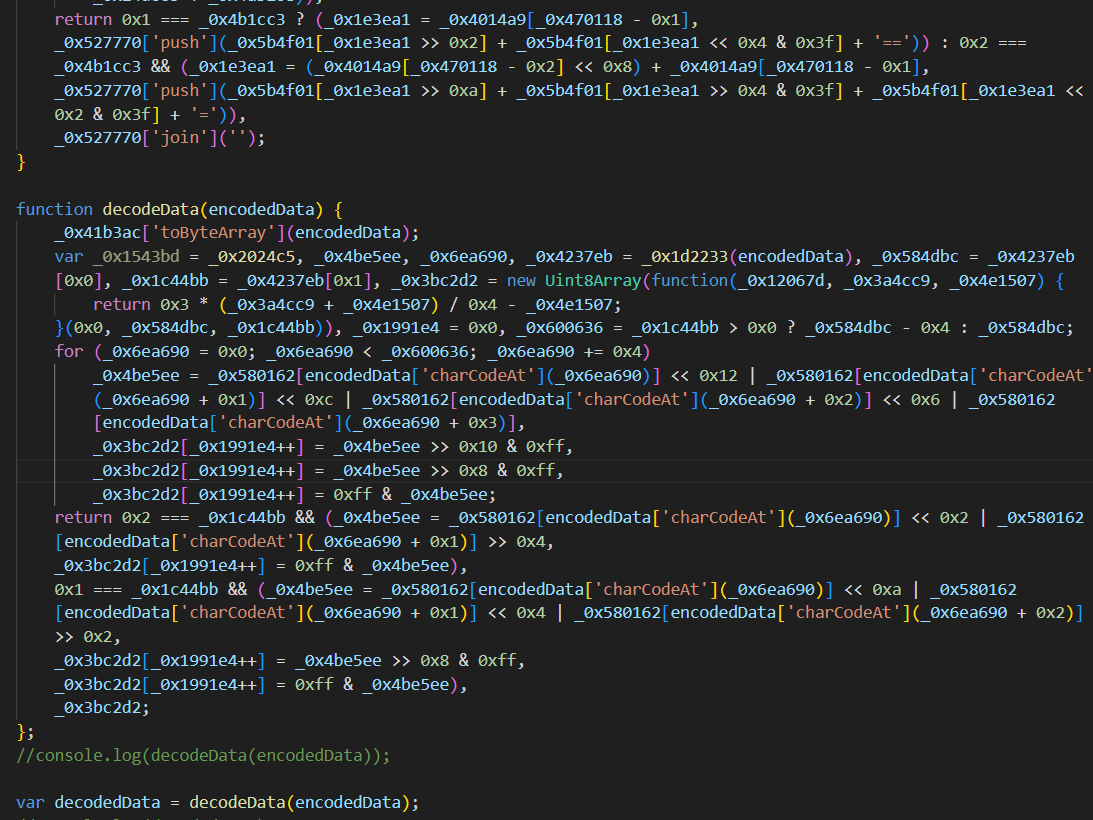
为了解决这个问题,我们计划开发一个爬虫。这个爬虫将会定期访问我们指定的网站,抓取最新的比赛内容,并将这些内容存储在我们的数据库中。
技术和方法:
我们计划使用Python语言开发这个爬虫,因为Python有很多成熟的爬虫库,如Scrapy、BeautifulSoup等,可以帮助我们快速开发爬虫。我们还会使用MySQL数据库来存储抓取到的新闻内容。
亮点介绍
高效的数据抓取: 爬虫能够快速并准确地从各种网站数据采集,大大提高了数据收集的效率。
强大的数据处理能力:还可以对数据进行清洗和格式化,易于分析和使用。
可以定期自动数据采集,节省了大量的人力资源。
定制化服务可以根据用户的具体需求,定制抓取的数据类型、数据源、抓取频率等。
成果展示
