


基于随机森林的肿瘤识别

无
随着现代生活节奏的加快,工作压力强度增加,癌症越来越趋于年轻化。当今我们处在科技发展先进的时代,科学防治癌症效果愈来愈好,癌症渐渐变成慢性病,但依然是有顽固性癌症的存在,而很多患者会讨论癌症应该如何治疗,如何治愈。真正的出发点是如何提早发现癌症,并利用现代的科技手段基本上能够控制和干预癌症扩散。因此,早发现早治疗对挽救患者生命尤为重要。如何预测肿瘤是良性还是恶性一直是癌症工作者的热点课题。
现有某医院某癌症的实例数据集,见附件1与附件2。请你们团队解决下面问题。
1.附件1中有 608个已知类别的肿瘤数据序列样本,包含特征属性和分类属性,其中分类属性中的2为良性,4为恶性。请建立分类属性与特征属性之间关系的数学模型,并评估你们所建模型的优良程度。
2.请预测附件2中各样本的分类属性,并分析结果的可靠性。
3.研究附件1中的样本数据,寻找癌症病例的标志性特征。
4.分析各因素对预测结果的显著性,并在此基础上,给出医疗工作者合理的建议。
随机森林模型的亮点:
集成学习:随机森林是一种集成学习方法,通过构建多个决策树并结合它们的预测结果来提高模型的稳定性与预测精度。这种方法可以减少过拟合的风险,并提高模型的泛化能力。
特征重要性:随机森林提供了一种计算特征重要性的方法,这有助于理解数据集中哪些特征对预测结果影响最大。这对于特征选择和理解数据有很高的价值。
处理高维数据:随机森林能够有效处理具有大量特征的数据集,无需进行特征选择,这在高维数据集上特别有用。
处理非线性关系:随机森林能够捕捉数据中的非线性关系,这对于复杂数据集的预测非常有用。
网格搜索调参的亮点:
系统性探索:网格搜索通过系统地遍历所有指定参数的组合,确保不会错过任何可能的最优参数组合,从而提高模型性能。
参数优化:通过网格搜索,可以找到较好的超参数设置,这些超参数可能包括树的数量、树的最大深度、特征选择比例等,这些参数的优化能够显著提升模型的预测性能。
避免过拟合:通过调整参数,可以控制模型的复杂度,避免模型在训练集上过拟合,提高模型在未知数据上的泛化能力。
减少人工试错:相比于手动尝试不同的参数组合,网格搜索自动化了这一过程,减少了人工试错
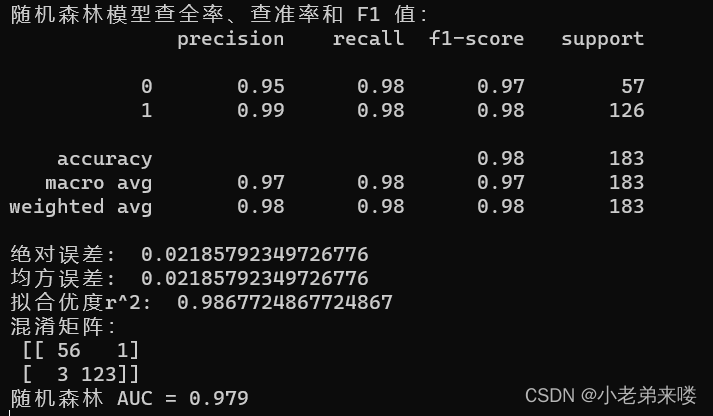
使用测试集对训练结果进行测试,准确率达到了0.979,拟合优度也有0.986之高,绝对误差与均方误差均只有0.02
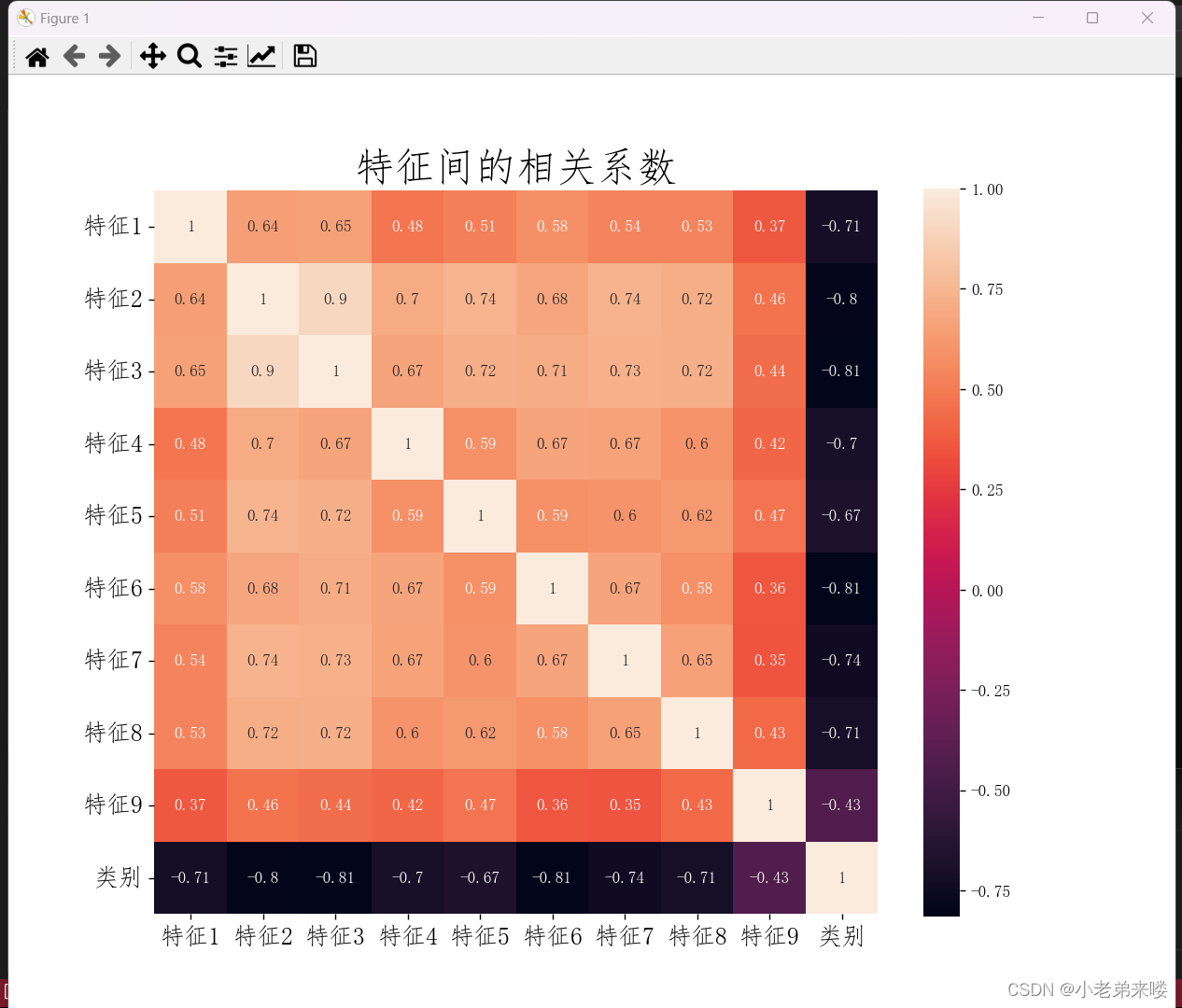
特征相关性分析,使用热力图的形式展现
