





AIGC定制AI微调Agent企业开发清华智谱百川大模型
智科技专业
客户信息
UE虚幻引擎定制开发需求
案例介绍
案例背景
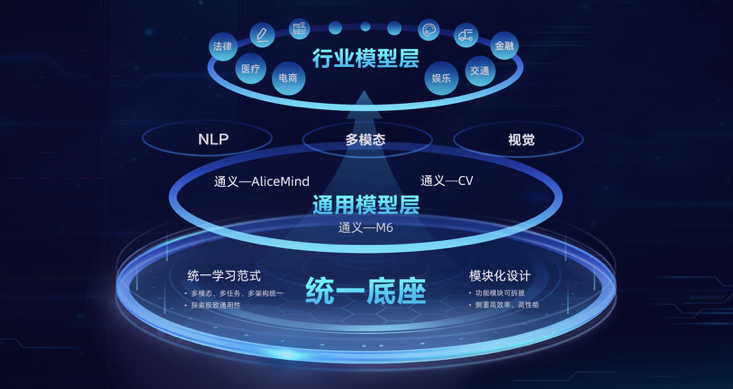
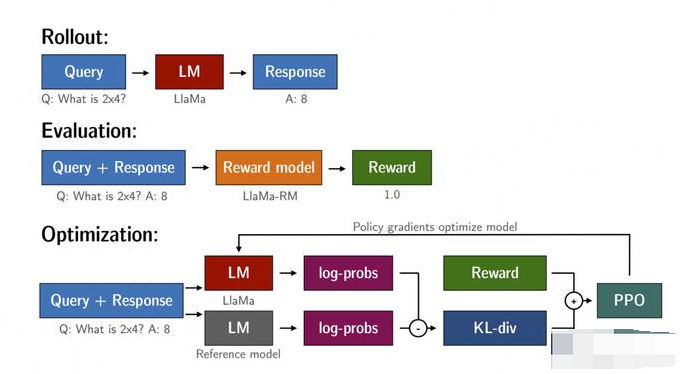
我们可基于大模型如llama\ChatGLM微调:文-文、文-图、文-视频定制开发,提供国内外大模型二次训练及私有化部署
数据预处理:将原始的文本数据进行清洗、分词、去停用词等操作使其符合模型的输入格式。
特征提取:将预处理后的文本数据转换为数值向量,以便于模型进行计算。
模型构建:选择合适的机器学习算法来构建分类器。
模型训练:使用标注好的训练集来训练分类器,通过优化损失函数来调整参数。
亮点介绍
我们可基于大模型如llama\ChatGLM微调:文-文、文-图、文-视频定制开发,提供国内外大模型二次训练及私有化部署
数据预处理:将原始的文本数据进行清洗、分词、去停用词等操作使其符合模型的输入格式。
特征提取:将预处理后的文本数据转换为数值向量,以便于模型进行计算。
模型构建:选择合适的机器学习算法来构建分类器。
模型训练:使用标注好的训练集来训练分类器,通过优化损失函数来调整参数。
成果展示
01
02
03
04
05
06