





版本内容
服务内容
基础版
定制服务
交付周期1天


服务介绍
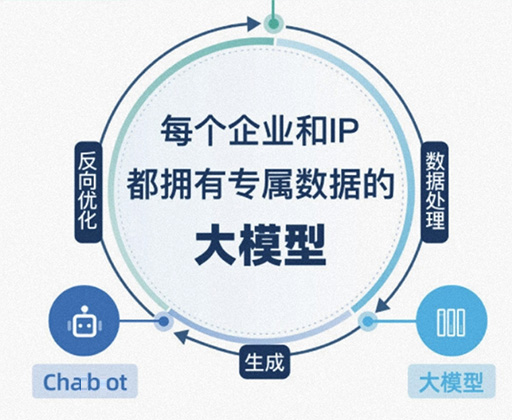
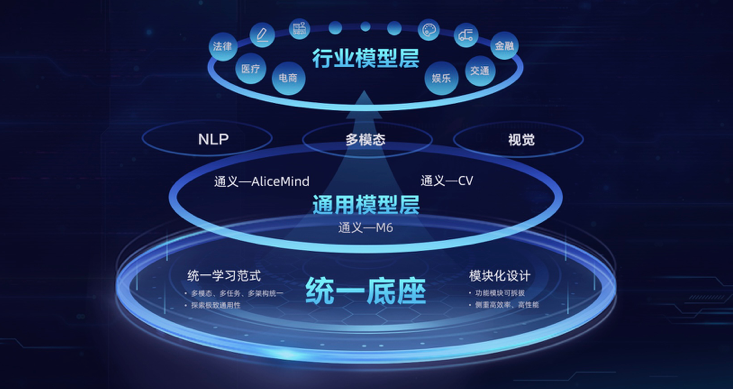
服务内容全部包含: 百川AI大语言模型训练清华智谱llama等数据集微调 1. 数据准备:首先,需要收集并准备一个大规模的文本数据集作为模型的训练数据。这个数据集可以包括各种类型的文本,如网页、新闻文章、小说、论文等。数据集的规模越大,模型的语言能力会相应更强。2. 数据预处理:在开始训练之前,需要对数据进行预处理。这可能包括删除无用的字符、标记化(将文本拆分成单词或子词单元)、构建词汇表等。 服务优势: 百川AI大语言模型训练清华智谱llama等数据集微调 1. 数据准备:首先,需要收集并准备一个大规模的文本数据集作为模型的训练数据。这个数据集可以包括各种类型的文本,如网页、新闻文章、小说、论文等。数据集的规模越大,模型的语言能力会相应更强。2. 数据预处理:在开始训练之前,需要对数据进行预处理。这可能包括删除无用的字符、标记化(将文本拆分成单词或子词单元)、构建词汇表等。 服务前需客户提供的信息: 百川AI大语言模型训练清华智谱llama等数据集微调 1. 数据准备:首先,需要收集并准备一个大规模的文本数据集作为模型的训练数据。这个数据集可以包括各种类型的文本,如网页、新闻文章、小说、论文等。数据集的规模越大,模型的语言能力会相应更强。2. 数据预处理:在开始训练之前,需要对数据进行预处理。这可能包括删除无用的字符、标记化(将文本拆分成单词或子词单元)、构建词汇表等。